
Gradient Descent
Batch Gradient Descent(BGD)
Let data has observations, model has parameter , loss function as , the gradient at point is , learning rate is . Then we have the formula:
So everytime we update our parameter, we need to compute whole data. Then this method is slow for large data size. But everytime it caculates the average gradient of whole data, the result is global optimization.
Stochastic Gradient Descent(SGD)
Not like BGD, every time it only use one data to caculate the gradient:
SGD is fast but easy to lead to a local optimization which means the accurate is decreased.
Min-batch Gradient Descent
Combine teh BGD abd SGD, it used a subset of data to do the update. We have times update and we select a subset size as where
When we have small dataset, we better use BGD. And in large dataset, we may use SGD or MBGD.
Least Square Method
Newton Method
For the target function : we find the Taylor Expression
Calculating the gradient for both side and ignore the above elements:
And we let and denote as Hessian matrix
So we start from , repeate calculate the until almost equal to 0
Quasi-Newton Method
Calculating the Hessian matrix every time cost a lot of computation. So there are many methods which find a similar Hessian matrix to finish the loop.
AdaGrad
It adjusted the learning rate for the different gradient at each features. Avoiding the same learning rate hard to fit all features.
Here is the function to update the parameter:
Where
- is the parameter need to be updated
- Is the initial learning rate
- is the some small quantity that used to avoid the division is 0
- is the identity matrix
- is the gradient estimate at time
- Matrix is the key point which is teh sum of the outer product of the gradients until time-step
Note that we can use full matrix but it is impractical especially in high-dimension problem. Hence we use the inverse the square root of the diagonal is easier to be computed.
Rewritting the AdaGrad function into matrix form:

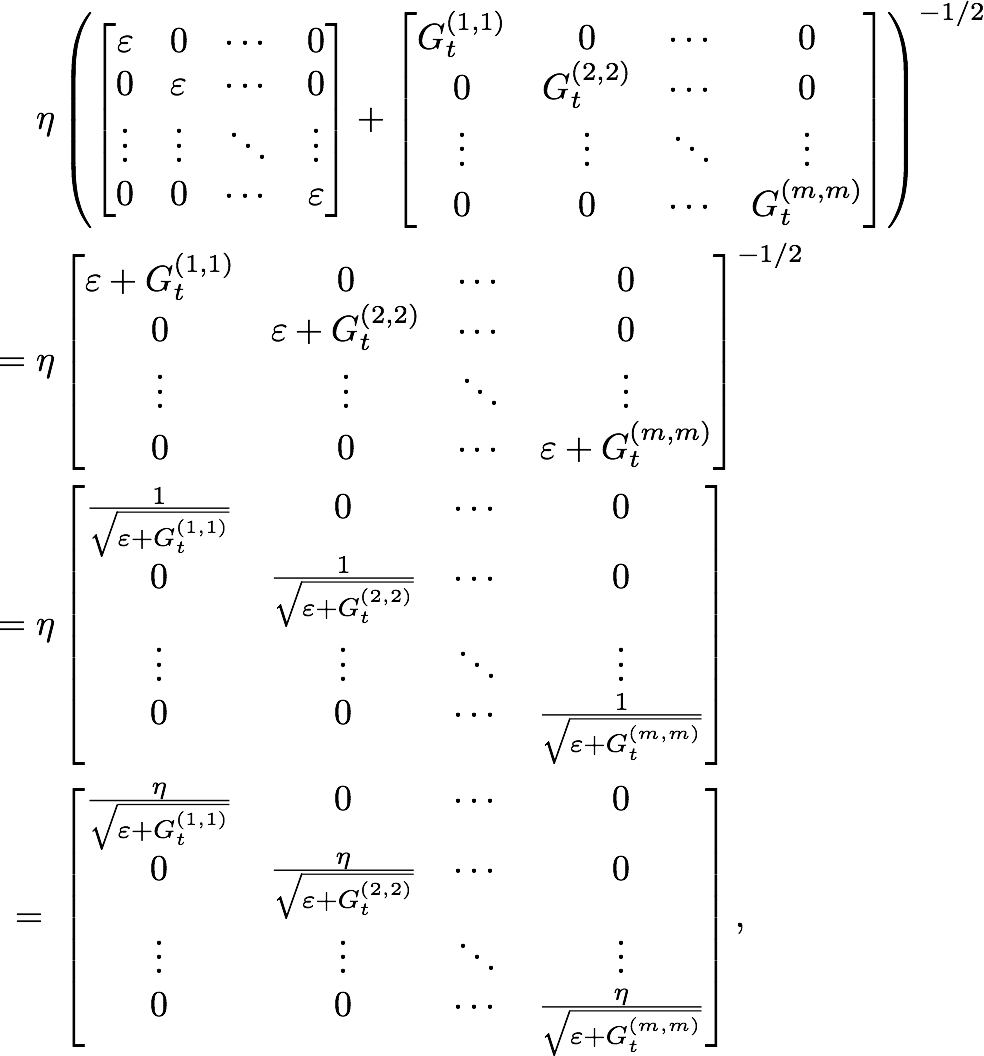
multiply
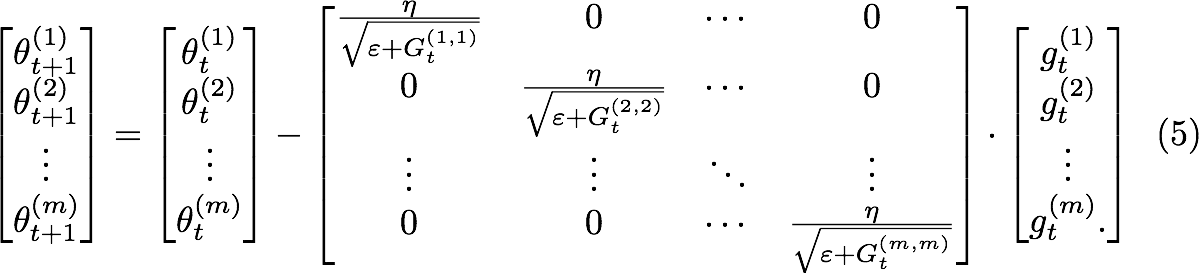
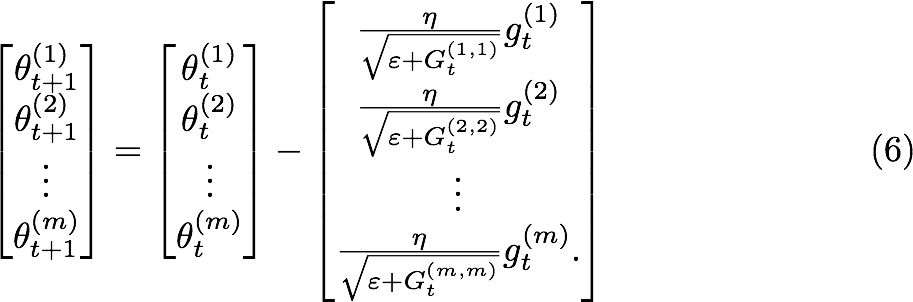
compare to the SGD(stochastic gradient descent)
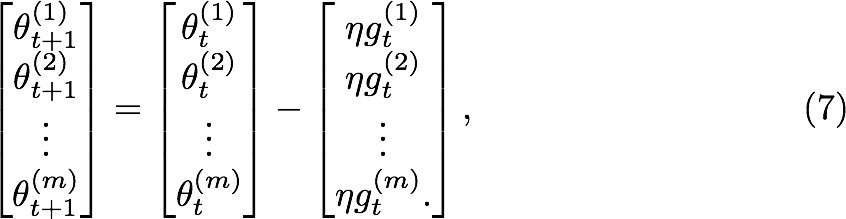
Where SGD used the same learning rate for each dimension. AdaGrad adapt the learning rate with the accumulated squared gradient at each iteration in each dimension.
AdaGrad algorithm performs best for sparse data because it decreases the learning rate faster for frequent parameters, and slower for parameters infrequent parameter. Unfortunately, there is some case that the effective learning rate `decreased very fast because we do accumulation of the gradients from the beginning of training. This can cause an issue that there is a point that the model will not learn again because the learning rate is almost zero.

