
## Regular Expression
1 | import re |
Square braces [ and ], match the first one meet this condition
1 | re.search("[tT]ed", "Ted or ted") |
Dash “-” represents the range
1 | re.search("[a-z]", "ABCabc") |
Caret “^”, if it is the first symbol after the open brace [ , the result is negated
1 | re.search("[^A-Z]", "ABCabc") |
Question mark “a?” means “a or nothing”
1 | re.search("abc?", "abc") |
Dot “.” means any character
1 | re.search("a.c", "a c") |
“|” means “and”. An alternator at this position effectively truncates the entire pattern, rendering any other tokens beyond this point useless
1 | re.search("cat|dog", "I like dog") |
“*” means Matches between zero and unlimited times, as many times as possible, giving back as needed (greedy), zero or more previous char.
“+” means one or more previous char.
“?” means zero or one of previous char
{n} means occurrences of the previous char
{n,m} means from to occurences of the previous char
{n,} and {,m} means at least and at most occurences of the precious char
" \ " means special notation such like ’ \ . ’ means “dot”
Corpora(语料库)
Text Normalization
unix tools
Introducing some Unix commands:
First we created a temp.txt file to try the following commands in the terminal :
1 | cat temp.txt |
output is (added some empty space to text)
1 | apple ,banana , Can, Again , 123 ,again, Banana, banana |
Then try “tr” means tokenize all non-alphabet sequence into a new line.
“A-Za-Z” means alphabet
-s means change all sequence into single char
-c means non-alphabet
This can split every single char into a line of this txt file:
1 | tr -sc "A-Za-Z" "\n" < name.txt |
output is:
1 | apple |
This can sort and count the word in this txt file:
1 | tr -sc "A-Za-z" "\n" < temp.txt | sort |uniq -c |
Output is:
1 | 1 Again |
Alterntively, we can tansfer all upper case letter to the lower case:
1 | tr -sc "A-Za-z" "\n" < temp.txt | tr A-Z a-z | sort |uniq -c |
output is;
1 | 2 again |
And we can sort the word by frequency: -n means sort numerically ranther than alphabetically, -r means reverse order
1 | tr -sc "A-Za-z" "\n" < temp.txt | tr A-Z a-z | sort |uniq -c | sort -n -r |
output is:
1 | 3 banana |
MaxMatch
Which choose longest word from current position to the end, and try to find whether there is a word match in dictionary. If not, then remove the last char. If yes, then skip these words and start again
nlp概要
nlp问题处理中,问题层面分为从细粒度到大: 词语,句子,段落&文章,文档
Bag of Words
构建词列表,计算频数
缺点: 高维问题,产生稀疏矩阵Sparse Matrix
TF-IDF
Term frequency - Inverse document frequency
词频 - 逆文本频率
TF: 词条t在文档d中出现的频率
IDF: 包含词条t的文档越少,也就是n越小,则IDF越大
一个词或短语在一篇文章中出现的频率很高,但在其他文章中出现频率较低,则认为它具有很好的类别划分能力。
计算文中每个词的TF-IDF,并通过卡方检验,判断词语是否独立scikit-learn.feature_selection_chi2. 后排序并取最高的为关键词。
优:
简单快速,易于理解
劣:
重要的词不一定出现的多,无法体现词的位置或上下文信息
Word Embedding
优:
包含上下文关系
劣:
需设置窗口大小
(From Towards Data Science)
Neural Networks are designed to learn from the numerical data, the Word Embedding is improving the ability to learn from text data.
The Word Embedding represents the text data into a lower dimensional vectors. These vectors are called Embedding.
The most general process is to use one hot encode our text: Which transforms all unique words as a feature. Since this computation cost a lot and the calculation between one-hot vector and the first hidden layer will result have mostly 0 values.
The the Word Embedding can solve this problem and make the calculation more efficiency. It creates a fully-connected layer which is embedding weights.
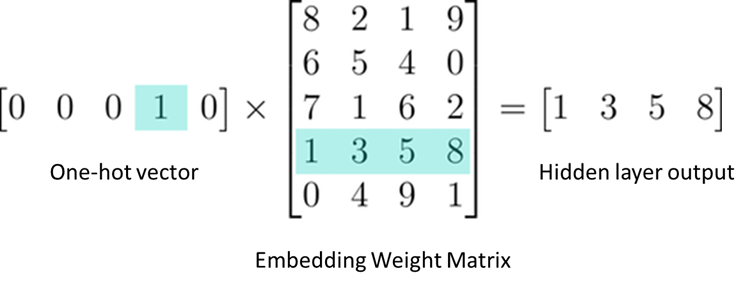
Hence if we need to calculate the Hidden layer output of a word, we only need to know the row number in the weight matrix which is called Embedding Lookup. Popular word embedding models are
-
Word2Vec:
Provided by Google and is trained by Google News data. This model has 300 dimnesions. It used skip-gram and negative sampling to build the model
-
GloVe:
Provided by Stanford, Used word-to-word co-occurence to build the model. If two words co-occur many times, it means they have some linguistic or semantic similarity.
-
fastText:
Provided by Facebook, Used character n-grams to do the word representations and sentence classifications.
Word2vec
将词语嵌入到数据空间,即为词嵌入wod embedding。word2vec (2013)即为词嵌入一种,将词语转化成词矩阵。
GloVe(2014) 采用共现矩阵分解
劣:
每个词对应一个向量
ELMo
2018年,基于GloVe,预训练好的模型将句子作为输入,根据上下文来推断每个词的向量,同词语在不同语句具有不同的含义(向量)。其模型结构决定了其双向学习,不同于LSTM的前向学习,类似于BiLSTM双向LSTM模型,使用了后向语言输入。最终为优化对数前向和后向的拟然函数。
ELMo使用多个网络层,词语token,双向LSTM。每一层将前向与后向LSTM输出拼接,每层向量乘以权重,每层目标函数:
独立训练并拼接
ELMo可用以有监督的nlp任务或是迁移学习transfer learning
优:
有助于多义词消歧义,BiLSTM越高层越能学习到词意信息
劣:
使用LSTM,但非Transformer(2017)。Transformer的特征提取能力远高于LSTM。
BERT
BERT (bidirectional encoder representation from transformers. 双向Transformer的Encoder
同时训练两个模型:Masked-language modeling(MLM),Next-sentence-prediction(NSP)
Masked-language modeling(MLM)
回归到Token级别学习,结合上下文,随机mask(10%替换其他单词,10%不替换,80%替换mask)增加了鲁棒性和信息表现representation的获取能力
却别于ELMo的每层输出拼接,Bert的目标函数为整体
Embedding 分为
- Token embedding 词向量,
- Segment Embedding,句子分类
- Position Embedding,位置
劣:
但会使某些词在fine-tune中没出现过,每个batch15%被预测,收敛慢
Next-sentence-prediction(NSP)
从句子层面学习语义特征,每个词向量为一个句子的函数,一个词在不同上下文有不同word-vector.
训练输入两个句子A,B。 判断B是否为A的下一句。
参数:batch size, Learning rate, number of epochs
Bert:预训练模型,向下迁移不错
优:Transformer相对RNN更高效,获取更长的距离的信息

